© IntegrationWise, 2026
This article explores the webMethods FLOW programming language. It gives a bit of background and then tries to link the resulting artefacts with the graphical presentation of the language in the IDE. It then continues to explore how to programmatically create FLOW code on the webMethods IntegrationServer.
Here is a preview of that FLOW service:
The nineties and the first decade of the millenium was the era of the System Integrators. They are (were?) consultancy companies that would help customers connect their Enterprise Applications (CRM systems, ERP systems, billing systems etc.) using specialized software: middleware. Like consultancy companies do, they hire fresh out of college and let their employees 'learn on the job'. In many cases, technical skills weren't the primary strength of those youngsters. Middleware vendors made therefore every effort to make their product as easy to use as possible. Interacting with an Enterprise Applications required an Adapter, typically with introspection capabilities so you could select the desired API from a dropdown list, and the available inputs and outputs would be auto-filled. The task of the integration consultant was to analyze the fields, create a mapping document and implement the mapping by drawing lines between corresponding fields.
So the designers of the IntegrationServer wanted a programming language that was easy to use. Really easy to use. Already around the turn of the millenium, ease of use was a big selling point. Relatively inexperienced consultants should be able to quickly create non-trivial integration solutions. Instead of writing text based code, a consultant would compose a FLOW-service that would orchestrate predefined building blocks - services - in order to reach a certain business goal.
The language should be graphical and support a drag-and-drop development style, yet have sophisticated debugging capablilities. The developer should be ignorant of the resulting code, but only be exposed to the graphical representation in the IDE. The room for syntax errors was to be kept to a minimum. The result was the FLOW language.
This post explores the inner workings of the FLOW programming language, rather than provide a detailed description of the language. The goal is to provide an in-depth understanding of FLOW code and how one create FLOW services programmatically.
The FLOW language supports only 7 constructs of which 6 are flow control constructs, while the seventh is meant for data mapping:
SEQUENCESEQUENCE has only one property that affects execution: when to exit, i.e. stop executing the next child step, either on:
 , CATCH
, CATCH  and FINALLY
and FINALLY  step were introduced. They are syntactic sugar implemented on top of the
step were introduced. They are syntactic sugar implemented on top of the SEQUENCE step and will be further ignored here.
BRANCHBRANCH evaluates the expressions of its children in order. The path
is taken of the first child whose expression evaluates to true.
LOOPREPEATwhile(true){ } construct in other languages. A REPEAT step executes its children one or more times. The counter
can be fixed, or made dependent of a variable. Optionally an interval can be specified. One can choose to repeat either on SUCCESS or on FAILURE.
EXITFAILURE and a message, the EXIT step turns into an exception.
MAPMAP one can:
INVOKEFor a detailed explanation of the various FLOW steps, please refer to the online documentation.
As one can see, the FLOW language itself is very small and in many ways very limited. It lacks even the most basic features that one would expect from a programming language:
In order to do anything meaningful, one has to use one of the predefined java services that come with the IntegrationServer, most notably in the WmPublic package.
However, the set of services in WmPublic is fairly limited. Very quickly packages with more advanced services were created, initially mainly by wM Professional Services employees, like the PSUtilities package, but there are also other initiatives, like the very popular Thundra package, available on GitHub. Of course, one can also define custom java services and as such extend the capabilities of the IntegrationServer.
All development on the IntegrationServer is done in Designer, an Eclipse based integrated development environment (IDE).
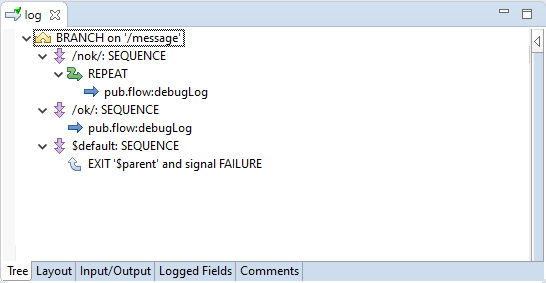
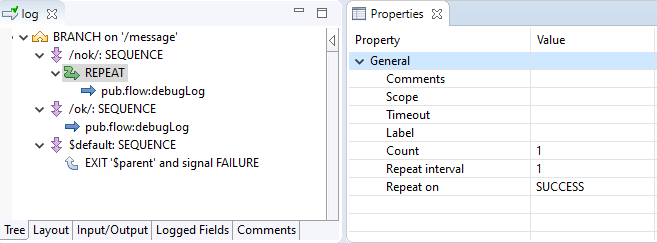
Let's examine the following simple example service sample.pub:log located in the SAMPLE package:
First we define inputs and outputs (although the flow service would work without them as well). Nevertheless, it's good practice to always diligently define the expected input and outputs. In this case we define a string field on the input named 'message' and an (optional) field on the output name 'level':
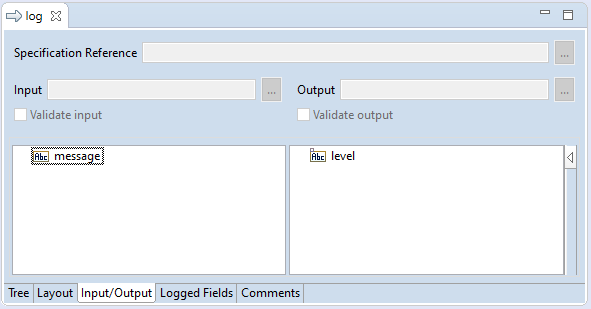
The example is perhaps somewhat contrived, but it serves for illustration purposes. Based on the value of message, one of three possible
routes is taken.
message contains 'nok', then the message is written to the server log twice with log level 'Error' (configured in a separate dialog).message contains 'ok', then the message is written to the server log with the default log level, which happens to be 'Info'.See the following picture for the FLOW code that implements this logic. The built-in service pub.flow:debugLog writes an entry
in the server log:
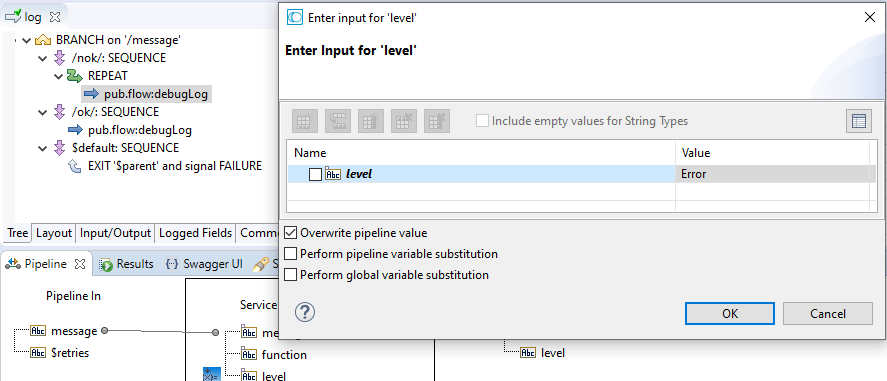
The service pub.flow:debugLog produces the field 'level'. But this field will not exist if the '$default' path is taken.
The configuration of the REPEAT step. It will execute pub.flow:debugLog twice, with an interval of 1 second:
The configuration of the invoke of pub.flow:debugLog
Upon saving this flow service to the IntegrationServer, two files are created (or updated):
$IS_HOME/packages/SAMPLE/ns/sample/pub/log/node.ndf $IS_HOME/packages/SAMPLE/ns/sample/pub/log/flow.xml
The node.ndf file contains the input and output definition and it tells the IntegrationServer what kind of 'node' it's dealing with. In
this case
<?xml version="1.0" encoding="UTF-8"?> <values version="2.0"> <value name="svc_type">flow</value> #It's FLOW service <value name="svc_subtype">default</value> #No particular sub type <!-- omitted --> </Values>
The flow.xml file contains the flow code. The important thing to notice about flow code, is that it has a
tree-like structure. Every element (MAP, BRANCH, SEQUENCE etc.) can be moved around freely,
without causing a syntax error. Of course, some constellations would not make any sense, but that would not make the code illegal.
Put differently, the developer composes graphically in Designer an abstract syntax tree or AST. In text based programming languages, this is an intermediate result after parsing the source code, but in FLOW it's the direct result of development.
The flow.xml file is a representation in XML-format of the FLOW code as it exists as an object, or better said, as a tree of objects
within the IntegrationServer. It is created when the developer
saves his or her work in Designer. It is read and parsed by the IntegrationServer when it starts up, and then loaded into memory, ready to be executed.
Another interesting thing to notice is that there is no meta information necessary about how to represent the code in Designer graphically. So there is no x-coordinate or y-coordinate for a FLOW step saved. The developer has no influence of how the code is represented. This is a direct consequence of the tree structure of the FLOW code.
Below you see the XML representation of the FLOW code of the sample.pub:log service, presented above. Each FLOW step corresponds to an XML element.
They're each highlighted in the text below. Attributes on the element further specify its operation.
Note: RETRY is the original name of the 'REPEAT'-step that is shown in the GUI.
<?xml version="1.0" encoding="UTF-8"?> <FLOW VERSION="3.0" CLEANUP="true"> #The root element of a flow service. <COMMENT/> <BRANCH TIMEOUT="" SWITCH="/message"> <COMMENT/> <SEQUENCE NAME="/nok/" TIMEOUT="" EXIT-ON="FAILURE"> <COMMENT/> <RETRY TIMEOUT="" COUNT="1" BACK-OFF="1" LOOP-ON="SUCCESS"> #RETRY is the original name of REPEAT <COMMENT/> <INVOKE TIMEOUT="" SERVICE="pub.flow:debugLog" VALIDATE-IN="$none" VALIDATE-OUT="$none"> <COMMENT/> <MAP MODE="INPUT"> <MAPTARGET><!-- omitted --></MAPTARGET> <MAPSOURCE><!-- omitted --></MAPSOURCE> <!-- nodes --> <MAPSET NAME="Setter" OVERWRITE="true" VARIABLES="false" GLOBALVARIABLES="false" FIELD="/level;1;0"> #Sets a fixed value on the field 'level' <DATA ENCODING="XMLValues" I18N="true"> <Values version="2.0"> <value= name="xml">Error</value> #Here is the value: 'Error' <record name="type" javaclass="com.wm.util.Values"> <value name="node_type">field</value> <value name="node_subtype">unknown</value> <value name="is_public">false</value> <value name="field_name">level</value> <value name="field_type">string</value> <value name="field_dim">0</value> <value name="field_opt">true</value> <array name="field_options" type="value" depth="1"> <value>Fatal</value> <value>Error</value> <value>Warn</value> <value>Info</value> <value>Debug</value> <value>Trace</value> <value>Off</value> </array> <value name="nillable">true</value> <value name="form_qualified">false</value> <value name="is_global">false</value> </record> </Values> </DATA> </MAPSET> </MAP> </INVOKE> </RETRY> </SEQUENCE> <SEQUENCE NAME="/ok/" TIMEOUT="" EXIT-ON="FAILURE"> <COMMENT/> <INVOKE TIMEOUT="" SERVICE="pub.flow:debugLog" VALIDATE-IN="$none" VALIDATE-OUT="$none"> <COMMENT/> </INVOKE> </SEQUENCE> <SEQUENCE NAME="$default" TIMEOUT="" EXIT-ON="FAILURE"> <COMMENT/> <EXIT FROM="$parent" SIGNAL="FAILURE" FAILURE-MESSAGE="Message should either contain 'ok' or 'nok'"> <COMMENT/> </EXIT> </SEQUENCE> </BRANCH> </FLOW>
There are a couple interesting things to notice:
MAP and its contained MAPSET under the INVOKE,
the code is quite concise. Each element (BRANCH, SEQUENCE, RETRY, INVOKE, EXIT)
only contains the necessary information and only occupies one line (well, two, if we count the closing tag as well).
MAP and the MAPSET on the INVOKE however are
very verbose. The MAPSET alone needs 26 lines just to give the field 'level' the fixed value of 'Error'.
flow.xml shown above, because they do not constitute any code, but are rather a help for the IDE.
The MAPTARGET element contains in reality 62 lines and the
MAPSOURCE element 16. These omitted lines represent the fields that are available for the mapping. They're calculated by Designer based
on the advertised inputs and outputs of the invoked services. In the example it is just pub.flow:debugLog,
but a more realistic flow service will call more than one service. All the advertised outputs and the used inputs will be added to the
MAPSOURCE element of the next INVOKE service. This will very quickly grow the size of the flow.xml file.
Flow services with a corresponding flow.xml file of 10MB are not unheard of.
sample.pub:log and the 'message' field on pub.flow:debugLog,
although the link is shown in the last picture. The reason is that the field 'message' is implicitly mapped, simply because the name of the field is the same.
MAPAs explained earlier, the MAP step is the only Flow element that can change the contents of the pipeline. Let's consider a flow service
with one empty MAP step, but with a label and a description. We'll use the service sample.pub:processCustomer
as an example:
The corresponding flow.xml file looks like this:
<?xml version="1.0" encoding="UTF-8"?> <FLOW VERSION="3.0" CLEANUP="true"> <COMMENT></COMMENT> <!-- nodes --> <MAP NAME="map" TIMEOUT="" MODE="STANDALONE"> #The Label becomes the name of the MAP <COMMENT>-- This is a map --</COMMENT> #The Comments go in the contents of the COMMENT element </MAP> </FLOW>
The empty MAP occupies only three lines.
Note that the service has defined inputs (name, external-ids, address and products) and outputs (code
and message). They are visible in the IDE in the Pipeline pane, but they do not show up in the flow.xml file.
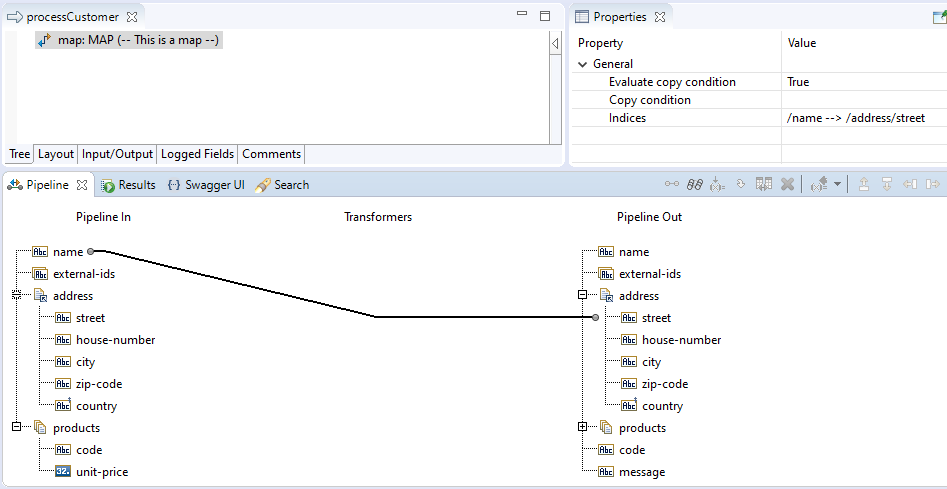
As a next step, let's map the field name to the field street under the address structure by
clicking on the name and dragging a line to address/street:
The corresponding flow.xml file now looks like this:
<?xml version="1.0" encoding="UTF-8"?> <FLOW VERSION="3.0" CLEANUP="true"> <COMMENT></COMMENT> <!-- nodes --> <MAPSOURCE><!-- omitted --><MAPSOURCE> <MAPTARGET><!-- omitted --><MAPTARGET> <MAP NAME="map" TIMEOUT="" MODE="STANDALONE"> #The Label becomes the name of the MAP <COMMENT>-- This is a map --</COMMENT> #The Comments go in the contents of the COMMENT element <MAPCOPY FROM="/name;1;0" TO="/address;4;0;sample.doc:address/street;1;0"> </MAPCOPY> </MAP> </FLOW>
The element MAP has become a child element MAPCOPY, representing the black line in the IDE. When this piece of
code executes, the value that is found under name is copied to address/street.
Notice that the FROM and TO attributes do not contain simple paths. Rather,
they contain typed paths into the pipeline. More about typed paths later.
Let's create another map, one that involves the unit-price. Let's map it to a new field called price,
but take it from the second item in the products list, and only copy if the second item in the external-ids
list matches '123':
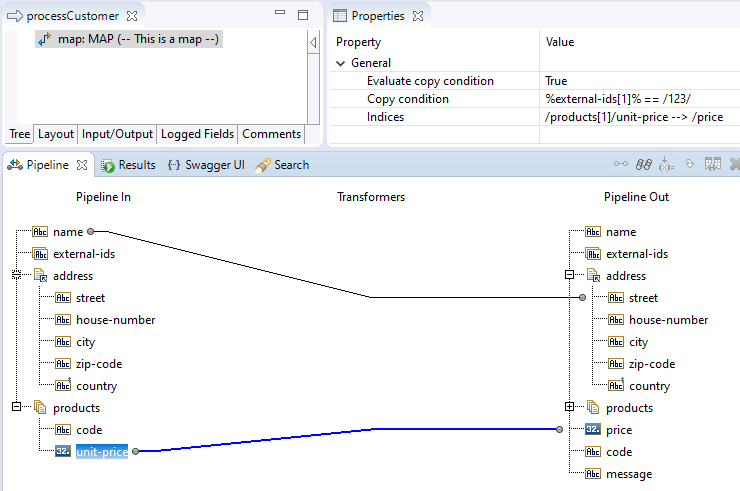
The effect in the flow.xml file is that there is now a second MAPCOPY element under the MAP element:
<?xml version="1.0" encoding="UTF-8"?> <FLOW VERSION="3.0" CLEANUP="true"> <COMMENT></COMMENT> <!-- nodes --> <MAPSOURCE><!-- omitted --><MAPSOURCE> <MAPTARGET><!-- omitted --><MAPTARGET> <MAP NAME="map" TIMEOUT="" MODE="STANDALONE"> #The Label becomes the name of the MAP <COMMENT>-- This is a map --</COMMENT> #The Comments go in the contents of the COMMENT element <MAPCOPY FROM="/name;1;0" TO="/address;4;0;sample.doc:address/street;1;0"> </MAPCOPY> <MAPCOPY FROM="/products[1];2;1/unit-price;3.5;0" TO="/price;3.5;0" CONDITION="%external-ids[1]% == /123/"> </MAPCOPY> </MAP> </FLOW>
Things to notice here:
java.util.Float) of the unit-price is 3.5. See the section about the Typed Path below.
CONDITION was entered by the developer in the IDE and appears unaltered in the flow.xml file. The condition can be really anything and refer to
other values in the pipeline. It does not have to refer to any of the fields mentioned in the FROM or TO attributes.
Let's now drop a value from the pipeline, for example external-ids
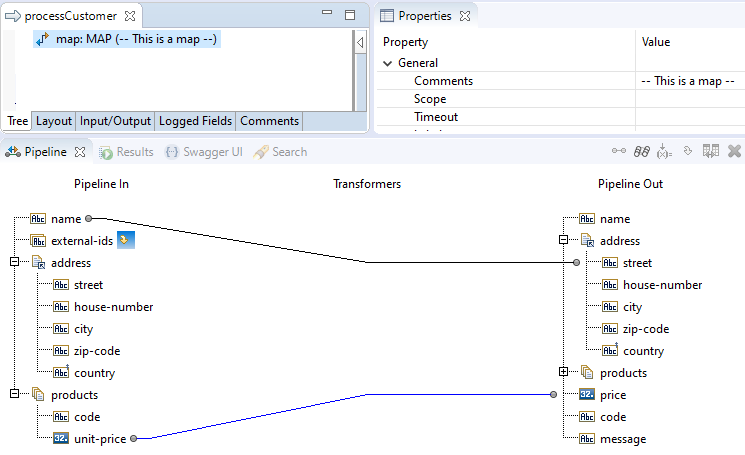
The effect in the flow.xml file is that there is now MAPDELETE element under the MAP element:
<?xml version="1.0" encoding="UTF-8"?> <FLOW VERSION="3.0" CLEANUP="true"> <COMMENT></COMMENT> <!-- nodes --> <MAPSOURCE><!-- omitted --><MAPSOURCE> <MAPTARGET><!-- omitted --><MAPTARGET> <MAP NAME="map" TIMEOUT="" MODE="STANDALONE"> #The Label becomes the name of the MAP <COMMENT>-- This is a map --</COMMENT> #The Comments go in the contents of the COMMENT element <MAPCOPY FROM="/name;1;0" TO="/address;4;0;sample.doc:address/street;1;0"> </MAPCOPY> <MAPCOPY FROM="/products[1];2;1/unit-price;3.5;0" TO="/price;3.5;0" CONDITION="%external-ids[1]% == /123/"> </MAPCOPY> <MAPDELETE FIELD="/external-ids;1;1"> </MAPDELETE> </MAP> </FLOW>
A dropped value disappears from the pipeline and is not available in further steps anymore. In the IDE, you see that external-ids
has disappeared from the 'Pipeline Out' pane, and has become the 'dropped value' icon in the left-hand pane 'Pipeline In'.
Let's now assign a fixed value to a variable in the pipeline, for example assign the value Socrates to name.
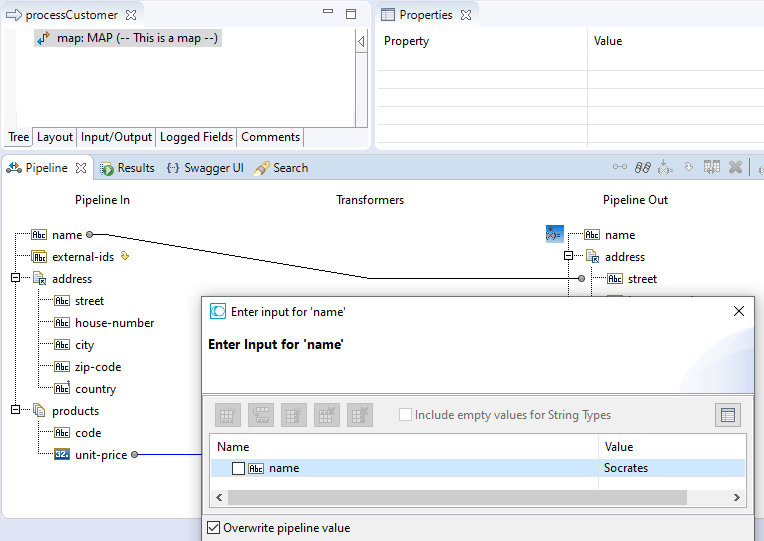
The effect in the flow.xml file is that there is now MAPSET element under the MAP element:
<?xml version="1.0" encoding="UTF-8"?> <FLOW VERSION="3.0" CLEANUP="true"> <COMMENT></COMMENT> <!-- nodes --> <MAPSOURCE><!-- omitted --><MAPSOURCE> <MAPTARGET><!-- omitted --><MAPTARGET> <MAP NAME="map" TIMEOUT="" MODE="STANDALONE"> #The Label becomes the name of the MAP <COMMENT>-- This is a map --</COMMENT> #The Comments go in the contents of the COMMENT element <MAPCOPY FROM="/name;1;0" TO="/address;4;0;sample.doc:address/street;1;0"> </MAPCOPY> <MAPCOPY FROM="/products[1];2;1/unit-price;3.5;0" TO="/price;3.5;0" CONDITION="%external-ids[1]% == /123/"> </MAPCOPY> <MAPDELETE FIELD="/external-ids;1;1"> </MAPDELETE> <MAPSET NAME="Setter" OVERWRITE="true" VARIABLES="false" GLOBALVARIABLES="false" FIELD="/name;1;0"> <DATA ENCODING="XMLValues" I18N="true"> <Values version="2.0"> <value name="xml">Socrates</value> #The actual value <record name="type" javaclass="com.wm.util.Values"> #Describes the field 'name' <value name="node_type">record</value> <value name="node_subtype">unknown</value> <value name="node_comment"/> <record name="node_hints" javaclass="com.wm.util.Values"> <value name="field_usereditable">true</value> <value name="field_largerEditor">false</value> <value name="field_password">false</value> </record> <value name="is_public">false</value> <value name="field_name">name</value> <value name="field_type">string</value> <value name="field_dim">0</value> <array name="field_options" type="value" depth="1"> </array> <value name="nillable">true</value> <value name="form_qualified">false</value> <value name="is_global">false</value> </record> </Values> </DATA> </MAPSET </MAP> </FLOW>
It takes apparently 26 lines in the flow.xml file to specify that the value of the string field name should be
assigned the value Socrates. The bulk of the verbosity lies in the meta-information of the field name that
is saved along with it.
When the IntegrationServer executes a MAP step, the MAPCOPY statements are executed before
the MAPDELETE and MAPSET statements. This means that:
MAPSET statement in the same MAP, the original value
is used in the MAPCOPY.
Finally, there is a way to manipulate the data in a mapping, for example to trim a value, or capitalize a word. In such cases one would use a Transformer.
Let's use one to capitalize the letters of address/city field.
This looks in the Pipeline Editor like this:
If you look closely, you see that a transformer is an invocation of a regular service, pub.string:toUpper in this case, but inside a MAP
step. A Transformer, like its name suggests, is intended to be used the way it's used here: to transform a string field.
However, nothing prevents one of calling a service that does more complicated things and in practice this happens quite often. One important reason to do this, is
that the pipeline that is passed to the transformer, only contains the values that are explicitly mapped into it. When a service is invoked in the regular way (like
pub.flow:debugLog in the first example), the complete pipeline is passed, possibly passing parameters that affect the service in undesirable ways.
The effect in the flow.xml file is that there is now a MAPINVOKE element under the MAP element. Within the MAPINVOKE
there are two other maps.
<?xml version="1.0" encoding="UTF-8"?>
<FLOW VERSION="3.0" CLEANUP="true">
<COMMENT></COMMENT>
<MAPSOURCE><!-- omitted --><MAPSOURCE>
<MAPTARGET><!-- omitted --><MAPTARGET>
<MAP NAME="map" TIMEOUT="" MODE="STANDALONE">
<COMMENT>-- This is a map --</COMMENT>
<!-- other maps omitted -->
<MAPINVOKE SERVICE="pub.string:toUpper" VALIDATE-IN="$none" VALIDATE-OUT="$none" INVOKE-ORDER="0">
<!-- nodes -->
<MAP MODE="INVOKEINPUT"> #The input map: /address/city -> inString
<MAPTARGET><!-- omitted --></MAPTARGET>
<MAPSOURCE><!-- omitted --></MAPSOURCE>
<MAPCOPY FROM="/address;4;0;sample.doc:address/city;1;0" TO="/inString;1;0">
</MAPCOPY>
</MAP>
<MAP MODE="INVOKEOUTPUT"> #The output map: /value -> /address/city
<MAPSOURCE><!-- omitted --></MAPSOURCE>
<MAPTARGET><!-- omitted --></MAPTARGET>
<MAPCOPY FROM="/value;1;0" TO="/address;4;0;sample.doc:address/city;1;0">
</MAPCOPY>
</MAP>
</MAPINVOKE>
</MAP>
</FLOW>
Notice the values of the MAP elements: INOKEINPUT respectively INVOKEOUTPUT. The
possible values for MODE are:
STANDALONE: if the map appears as a step in a flow service.INPUT: maps the input of an INVOKE step.OUTPUT: maps the output of an INVOKE step.INVOKEINPUT: maps the input of an Transformer inside a MAP step.INVOKEONPUT: maps the output of an Transformer inside a MAP step.It's good to realize that the MAP elements are containers for:
MAPSET: sets the value of a field.MAPCOPY: copies a value from one field to another.MAPDELETE: deletes (or drops) a value from the pipeline.MAPINVOKE: invokes a service as a transformer inside a MAP step.The IDE infers the Typed Path from the line that was drawn by the user. A typed path differs from a simple, untyped path, described here, in that it carries extra information about the type of field, namely:
The extra information is added to the element of the path, separated by a semi-colon.
In the example above, the FROM path is /name;1;0. The
field name is name, the data type is 1 and the dimension is 0.
Similarly, the TO path is /address;4;0;sample.doc:address/street;1;0. The first part of the path
describes the address. The field name is address, the data type is 4, the dimension is 0
and the Document Type Reference is sample.doc:address.
The following tables help understand the meaning of values for dimension and data type. The central class here is com.wm.lang.ns.NSField.
This class plays a dual role. First, it represents a Document Type in the Namespace of the IntegrationServer, like sample.doc:address.
Secondly, it represents a field (of any type) inside a Document Type. In the latter case, there is no namespace name associated with the field.
The following table describes the main data types that the IntegrationServer recognizes:
| Name | Class Field | Value |
|---|---|---|
| String | NSField.FIELD_STRING | 1 |
| Document | NSField.FIELD_RECORD | 2 |
| Object | NSField.FIELD_OBJECT | 3 |
| Document Reference | NSField.FIELD_RECORDREF | 4 |
The data type Object may be further classified by a Java Wrapper Type. The central class here is com.wm.util.JavaWrapperType, see the following table:
| Java Type | Class Field | Value |
|---|---|---|
| Unknown | JavaWrapperType.JAVA_TYPE_UNKNOWN | 0 |
| java.lang.Boolean | JavaWrapperType.JAVA_TYPE_BOOLEAN | 1 |
| java.lang.Byte | JavaWrapperType.JAVA_TYPE_BYTE | 2 |
| java.lang.Character | JavaWrapperType.JAVA_TYPE_CHARACTER | 3 |
| java.lang.Double | JavaWrapperType.JAVA_TYPE_DOUBLE | 4 |
| java.lang.Float | JavaWrapperType.JAVA_TYPE_FLOAT | 5 |
| java.lang.Integer | JavaWrapperType.JAVA_TYPE_INTEGER | 6 |
| java.lang.Long | JavaWrapperType.JAVA_TYPE_LONG | 7 |
| java.lang.Short | JavaWrapperType.JAVA_TYPE_SHORT | 8 |
| java.lang.DATE | JavaWrapperType.JAVA_TYPE_DATE | 9 |
| byte[] | JavaWrapperType.JAVA_TYPE_byte_ARRAY | 10 |
| java.lang.BigDecimal | JavaWrapperType.JAVA_TYPE_BIG_DECIMAL | 11 |
| java.lang.BigInteger | JavaWrapperType.JAVA_TYPE_BIG_INTEGER | 12 |
| com.wm.util.XOPObject | JavaWrapperType.JAVA_TYPE_XOP_OBJECT | 13 |
| Dimension | Class Field | Value |
|---|---|---|
| Scalar | NSField.DIM_SCALAR | 0 |
| Array | NSField.DIM_ARRAY | 1 |
| Two-dimensional Array | NSField.DIM_TABLE | 2 |
The IntegrationServer actually uses the information contained the Typed Path when executing a MAPCOPY, MAPSET or MAPDELETE.
When the path is a source (in case of a MAPDELETE or the FROM attribute of a MAPCOPY), it looks for a variable of the indicated name, type and dimension.
If not all three conditions are met, nothing happens. The value is not dropped or the copy does not happen. This does not constitute an error.
When the path is a target (in case of a MAPSET of the TO attribute of a MAPCOPY), it also looks for a variable of the
indicated name, type and dimension. If it does not find one, then a field with those properties is created. Without the type and dimension information, the IS would not
know what to create.
Everything that can be done in Designer manually, can also be done programmatically. The only library that one needs
to create the Input/Output signature and the implementation, is the standard IS client library $WM_HOME/common/lib/wm-isclient.jar.
The original approach was to create the FLOW code in an IS-client and then connect to the IS in order to save the code, just like Designer does.
For saving the flow service on the IS one needs to invoke the either the IS service wm.server.ns:makeNode or wm.server.ns:putNode, depending
on whether the service already exists.
However, creating an instance of the required abstract class com.wm.lang.flow.FlowService proves not to be trivial. And also some extra client jars
are required to actually set up the connection and invoke the above mentioned services. So let's abandone that avenue in favour of an implementation directly
on the IS in a Java Service.
With the understanding of FLOW we have so far, let's try and
create the sample.pub:log flow service that was introduced in the first example.
A Flow Service has a few characteristics:
com.wm.lang.ns.NSNamecom.wm.lang.ns.NSNodeTypecom.wm.lang.ns.NSService
com.wm.ns.lang.NSSignature. Inputs and outputs can be defined inline, as was done for
the sample.pub:log service, but they can also be a reference to a Document Type
that's defined elsewhere, as was done for the sample.pub:processCustomer service.
Let's first create the Input/Output Signature. The input contains an string field named message
and is defined inline. The output contains the optional string field level.
A field is implemented by the class com.wm.lang.ns.NSField. If the field is supposed to
be a container, i.e. it can contain other fields, then the field type is NSField.FIELD_RECORD, and then
implemented by the class com.wm.lang.ns.NSRecord, which extends com.wm.lang.ns.NSField.
In the following piece of code, the (static) method createLogServiceSignature() produces the NSSignature,
which we will need later on to create the flow service.
import com.wm.lang.ns.NSField; import com.wm.lang.ns.NSRecord; import com.wm.lang.ns.NSSignature; public final class generateLogFlowService_SVC { // --- <<IS-BEGIN-SHARED-SOURCE-AREA>> --- private static NSSignature createLogServiceSignature() { //Create the service input signature: NSRecord inSig = new NSRecord(null, "in", NSField.DIM_SCALAR); //one (mandatory) input field: 'message' NSField messageField = new NSField(null, "message", NSField.FIELD_STRING, NSField.DIM_SCALAR); messageField.setComment("The message to write to the server log."); //add the 'message' field to the input signature. inSig.addField(messageField); //Create the service output signature NSRecord outSig = new NSRecord(null, "out", NSField.DIM_SCALAR); NSField levelField = new NSField(null, "level", NSField.FIELD_STRING, NSField.DIM_SCALAR); levelField.setComment("The log level that used to write to the server."); levelField.setOptional(true); //add the 'level' field to the output signature. outSig.addField(levelField); //Combine the input and output in a NSSignature return new NSSignature(inSig, outSig); } // --- <<IS-END-SHARED-SOURCE-AREA>> --- }
Note that the definition of the signature does not depend on any other class than NSField, NSRecord and
NSSignature. The method is completely stand-alone.
The NSSignature will end up in the node.ndf file.
Next up is the flow code itself. The serialized version of this will end up in the flow.xml file.
Here is a list of the relevant classes:
| Class | Description |
|---|---|
com.wm.lang.flow.FlowElement |
This is the base class of all other flow language classes. It defines the five properties they all have in common:
FlowElement.
Relevant methods:
public void setName(String); //This is the 'Label' public void setScope(String); public void setComment(String); public void setTimeoutString(String); //in seconds public void setEnabled(boolean); public void addNode(FlowElement);A note about the Timeout: this setting one will cause the Flow engine to throw a com.wm.lang.flow.FlowTimeoutException if a step takes
longer to complete than the specified amount of time. It will not interrupt the execution after the specified numbers of seconds
have passed.
|
com.wm.lang.flow.FlowRoot |
This represent to starting point of a flow service. It does not do anything and it's not visible in Designer. It serves no other purpose than being the container for the flow steps. |
com.wm.lang.flow.FlowBranch |
Implements the BRANCH step. Relevant methods:
public void setBranchSwitch(String); public void setIsCondition(boolean);The two properties are mutually exclusive. If a path to a value to 'branch' on is given, then 'isCondition' must be false, and vice versa.
The latter method corresponds to the property in Designer named 'Evaluate Labels'.
|
com.wm.lang.flow.FlowSequence |
Implements the SEQUENCE step, and as of 10.3 also the TRY, CATCH, FINALLY steps.
Relevant method:
public void setExitOn(int)
Valid values for the integer:
|
com.wm.lang.flow.FlowLoop |
Implements the LOOP step. Relevant methods:
public void setInArray(String); public void setOutArray(String); |
com.wm.lang.flow.FlowRetry |
Implements the REPEAT step. 'Retry' is the old name for REPEAT. Relevant methods:
public void setBackoffString(String); public void setCountString(String); public void setReapeatOn("FAILURE"|"SUCCESS"); //the typo is no typo |
com.wm.lang.flow.FlowMap |
Implements the various maps: STANDALONE, INPUT, OUTPUT, INVOKEINPUT, INVOKEOUTPUT. This class is actually a container. It's the parent of one or
more FlowInvoke, FlowMapDelete, FlowMapCopy or FlowMapSet objects. Relevant methods:
public void addNode(FlowElement);
|
com.wm.lang.flow.FlowExit |
Implements the EXIT step. Relevant methods:
public void setSignal("FAILURE"|"SUCCESS"); public void setExitFrom("$flow"|"$loop"|"$parent"); public void setFailureMessage(String); |
com.wm.lang.flow.FlowInvoke |
Invokes another service (of any type). Relevant methods:
public void setService(NSName); public void setValidateOut("$none"|"$default"); public void setValidateIn("$none"|"$default"); public void setInputMap(FlowMap); //from FlowElement; public void setOutputMap(FlowMap); //from FlowElement; |
com.wm.lang.flow.FlowMapInvoke |
Implements the Transformer. It subclasses FlowInvoke. Relevant methods:
public void setInputMap(FlowMap); public void setOutputMap(FlowMap); |
com.wm.lang.flow.FlowMapCopy |
Copies a value from one location in the pipeline to another. Relevant methods:
public void setMapFrom(String); //Expects a typed path public void setMapTo(String); //Expects a typed path |
com.wm.lang.flow.FlowMapSet |
Set the value of a field in the pipeline. Relevant methods:
public void setField(String); //Expects a typed path public void setInput(Object); //Can be a String or and IData object public void setInputType(NSField); //Describes the structure of the input (optional) |
com.wm.lang.flow.FlowDelete |
Drops a field from the pipeline. Relevant method:
public void setField(String); //Expects a typed path
|
In the java code below, the method composeLogServiceFlow() builds the FlowRoot object, which consitutes the actual FLOW code:
import com.wm.lang.flow.FlowBranch; import com.wm.lang.flow.FlowExit; import com.wm.lang.flow.FlowInvoke; import com.wm.lang.flow.FlowMap; import com.wm.lang.flow.FlowMapSet; import com.wm.lang.flow.FlowRetry; import com.wm.lang.flow.FlowRoot; import com.wm.lang.flow.FlowSequence; import com.wm.lang.ns.NSField; import com.wm.lang.ns.NSName; import com.wm.lang.ns.NSRecord; import com.wm.lang.ns.NSSignature; import com.softwareag.util.IDataMap; ... public final class generateLogFlowService_SVC { // --- <<IS-BEGIN-SHARED-SOURCE-AREA>> --- private static NSSignature createLogServiceSignature() {...} private static FlowRoot composeLogServiceFlow() { //Create the flow root FlowRoot flow = new FlowRoot(IDataFactory.create()); //Create the BRANCH, branch on 'message': FlowBranch branch = new FlowBranch(IDataFactory.create()); branch.setIsCondition(false); branch.setBranchSwitch("message"); //Create the first SEQUENCE, Label = '/nok/': FlowSequence firstSequence = new FlowSequence(IDataFactory.create()); firstSequence.setName("/nok/"); //This is the 'Label' //Create the REPEAT, Count = 1, Repeat interval = 1, Repeat on: SUCCESS: FlowRetry retry = new FlowRetry(IDataFactory.create()); retry.setBackoffString("1"); retry.setCountString("1"); retry.setReapeatOn("SUCCESS"); //Create the INVOKE for 'pub.flow:debugLog' with 'level' = 'Error', no input/output validation: FlowInvoke debugLogError = new FlowInvoke(IDataFactory.create()); debugLogError.setService(NSName.create("pub.flow:debugLog")); debugLogError.setValidateIn("$none"); debugLogError.setValiateOut("$none"); //Create the input MAP for the INVOKE FlowMap invoke_input_map = new FlowMap(null); //Create the MAPSET for 'level' = 'Error' FlowMapSet levelSet = new FlowMapSet(IDataFactory.create()); levelSet.setField("/level;1;0"); levelSet.setInput("Error"); levelSet.setName("Setter"); levelSet.setVariables(false); //Add the MAPSET to the MAP and the MAP as the input map to the invoke: invoke_input_map.addNode(levelSet); debugLogError.setInputMap(invoke_input_map); //Create the second SEQUENCE, Label = '/ok': FlowSequence secondSequence = new FlowSequence(IDataFactory.create()); secondSequence.setName("/ok/"); //This is the 'Label' //Create the INVOKE for 'pub.flow:debugLog' with ('level' not explicitly set) FlowInvoke debugLogDefault = new FlowInvoke(IDataFactory.create()); debugLogDefault.setService(NSName.create("pub.flow:debugLog")); //Create the third SEQUENCE, Label = '$default' FlowSequence thirdSequence = new FlowSequence(IDataFactory.create()); thirdSequence.setName("$default"); //This is the 'Label' //Create the EXIT, Exit from: '$parent', Signal: FAILURE, Failure message: 'Message should either contain 'ok' or 'nok'' FlowExit exit = new FlowExit(IDataFactory.create()); exit.setExitFromParent(); exit.setSignal("FAILURE"); exit.setFailureMessage("Message should either contain 'ok' or 'nok'"); //Build the tree //Start by adding the BRANCH to the FLOW flow.addNode(branch); //first SEQUENCE branch.addNode(firstSequence); firstSequence.addNode(retry); retry.addNode(debugLogError); //second SEQUENCE branch.addNode(secondSequence); secondSequence.addNode(debugLogDefault); //third SEQUENCE branch.addNode(thirdSequence); thirdSequence.addNode(exit); return flow; } // --- <<IS-END-SHARED-SOURCE-AREA>> --- }
Now that we have the Input/Output signature and the flow code, we can register the flow service with in the IntegrationServer. Two extra pieces of information are needed:
sample.pub:log2. The class.method to use for this is
com.wm.lang.ns.NSName.create("sample.pub:log2");
SAMPLE
The ServerAPI exposes a method to create a flow service:
com.wm.app.b2b.server.ServerAPI.registerFlowService(String package, NSName serviceName, FlowRoot flow, NSSignature signature);
In the code below, the method createSampleLogFlowService()puts it all together and creates the complete flow service, which
can immediately be used:
import com.wm.data.*; import com.wm.util.Values; import com.wm.app.b2b.server.Service; import com.wm.app.b2b.server.ServiceException; import com.wm.app.b2b.server.ServiceSetupException; import com.wm.app.b2b.server.ServerAPI; import com.wm.lang.flow.FlowBranch; import com.wm.lang.flow.FlowExit; import com.wm.lang.flow.FlowInvoke; import com.wm.lang.flow.FlowMap; import com.wm.lang.flow.FlowMapSet; import com.wm.lang.flow.FlowRetry; import com.wm.lang.flow.FlowRoot; import com.wm.lang.flow.FlowSequence; import com.wm.lang.ns.NSField; import com.wm.lang.ns.NSName; import com.wm.lang.ns.NSRecord; import com.wm.lang.ns.NSSignature; import com.softwareag.util.IDataMap; public final class generateLogFlowService_SVC { // --- <<IS-BEGIN-SHARED-SOURCE-AREA>> --- private static void createSampleLogFlowService() throws ServiceException { NSSignature signature = createLogServiceSignature(); FlowRoot flow = composeLogServiceFlow(); try { ServerAPI.registerFlowService("SAMPLE", NSName.create("sample.pub:log2"), flow, signature); } catch (ServiceSetupException e) { throw new ServiceException(e); } } private static NSSignature createLogServiceSignature() {...} private static FlowRoot composeLogServiceFlow() {...} // --- <<IS-END-SHARED-SOURCE-AREA>> --- }
The resulting flow.xml should look exactly like this (minus the 'pretty print' formatting), only 36 lines of XML code (of which 8 are comments):
<?xml version="1.0" encoding="UTF-8"?> <FLOW VERSION="3.0" CLEANUP="true"> <!-- nodes --> <BRANCH SWITCH="/message"> <!-- nodes --> <SEQUENCE NAME="/nok/" EXIT-ON="FAILURE"> <!-- nodes --> <RETRY COUNT="1" BACK-OFF="1" LOOP-ON="SUCCESS"> <!-- nodes --> <INVOKE SERVICE="pub.flow:debugLog" VALIDATE-IN="$none" VALIDATE-OUT="$none"> <!-- nodes --> <MAP MODE="INPUT"> <!-- nodes --> <MAPSET NAME="Setter" OVERWRITE="true" VARIABLES="false" GLOBALVARIABLES="false" FIELD="/level;1;0"> <DATA ENCODING="XMLValues" I18N="true"> <Values version="2.0"> <value name="xml">Error</value> </Values> </DATA> </MAPSET> </MAP> </INVOKE> </RETRY> </SEQUENCE> <SEQUENCE NAME="/ok/" EXIT-ON="FAILURE"> <!-- nodes --> <INVOKE SERVICE="pub.flow:debugLog"> </INVOKE> </SEQUENCE> <SEQUENCE NAME="$default" EXIT-ON="FAILURE"> <!-- nodes --> <EXIT FROM="$parent" SIGNAL="FAILURE" FAILURE-MESSAGE="Message should either contain 'ok' or 'nok'"> </EXIT> </SEQUENCE> </BRANCH> </FLOW>
This code executes exactly the same as the example flow sample.pub:log. Comparing this version of flow.xml with the one created through the IDE yields these differences:
TIMEOUT="". This attribute apparently gets added by Designer automatically. Its absence
in the code that we generated programmatically does not alter the execution logic.
COMMENT element. They are also added automatically by the IDE. Their absence does not affect the logic.MAPSOURCE or MAPTARGET element. These elements are also added automatically by the IDE and provide meta information
for the MAP steps. They get created by calling this method on a FlowMap instance:
public void setSchemaInfo(NSRecord sourceSchema, NSRecord targetSchema);
Their absence (again)1 does not affect the execution logic.
type information on the MAPSET element. That gets added by calling this method on a FlowMapSet instance:
public void setInputType(NSRecord);
MAPSET and MAPCOPY statements appear in the flow.xml
file, then the order defined in the schema is followed. Normally it does not matter in which order key-value pairs appear,
unless the structure is serialized into XML, CSV or JSON (or something else) and no additional schema information is supplied
during serialization.The IDE hides the implementation from the developer. One has to be aware of the fact that a map only moves links to java objects around. A line drawn in the Pipeline editor only gives an existing object an extra name. For example, if one maps from one Document to another and starts manipulating fields in the 'new' document, then the fields in the original document are also affected. This might easily trip up unexperienced developers.