© IntegrationWise, 2026
This article aims to describe and analyze the webMethods IntegrationServer in detail, in an effort to explain how it could serve its purpose over all those years without becoming obsolete. The IntegrationServer is best compared with the J2EE application servers that gained much popularity in the era between 2000 and say 2015: JBoss, WebSphere, WebLogic, Oracle Application Server etc. It is a runtime that can host 'enterprise'-like logic, while offering a low-code programming environment. This made it very suitable to be used by system integrators (consultancy companies) to build integration solutions for their customers (banks, insurance companies etc.) employing young consultants with not too much programming experience. In just a couple of years in the early 2000's webMethods was sold to a sizable portion of the Fortune 500 companies.
The webMethods IntegrationServer is the core component of the webMethods™ Integration Platform, a software suite aimed at providing the ability to integrate applications (A2A) and businesses (B2B) with each other. It was originally developed by the company webMethods (WEBM) back in 1996. The company went public during the height of the dotcom era around 2000. Further details can be found on Wikipedia.
webMethods Inc. quickly acquired a couple of companies in order to build an integration platform around their IntegrationServer (which was originally named 'B2BServer'):
In 2007, SoftwareAG, a software company based out of Darmstadt, Hessen, Germany, with a strong and successful history in building software for mainframes (most notably programming language Natural and the RDBMS ADABAS), acquired webMethods. This was no doubt as a strategic move to maintain its position as a major supplier of enterprise software.
In 2024 IBM acquired the webMethods Integration Platform, including StreamSets from SoftwareAG.
Despite all the changes in ownership, mergers and the addition of the new functionality, at the core of the webMethods Integration Platform remains after almost 30 years the IntegrationServer, still very much recognizable from its first years.
The IntegrationServer (also referred to as 'IS' from here on) dates back to 1996, just a year after the creation of the java language, in which the IS would be written. At that time J2EE hadn't seen the light of day, yet the IS had to provide 'enterprise'-like capabilities. Initially the IS was called 'B2B Server', as its main purpose was to exchange data (UNEDIFACT, X12 and XML messages) with business partners in the then rapidly developing business-to-business market. The 'b2b' history is visible in for example in the namespace of many java classes. The main class of the IS is:
com.wm.app.b2b.server.Server
An early partnership with SAP enabled the development of a bidirectional SAP adapter (the WmSAP package), which helped establish the IntegrationServer as one of the most capable applications for interacting with SAP.
webMethods, and neither SAG, never made an effort to make the IS a J2EE conformant application server, although later a WmTomcat package was added, which allowed one to deploy J2EE archives (.wars) on the IS. Some other industry standards were adopted:
The original designers of the IntegrationServer had a couple of capabilities in mind that the IS should have:
The first requirement let the implementers choose the then very new Java platform, which promised Write once, run anywhere capabilities. Windows NT was getting traction at that time as a server and was starting to compete with established UNIX servers from SUN, HP and IBM. The choice for Java would offer more development and deployment options.
The IntegrationServer needed an internal data structure that supported all imaginable serialization formats. Parsing and serializing should be reversable activities. That means that serializing a parsed external document, should result in the same document. Let's use a simple example to illustrate. Let's suppose that an external partner sent the following order to the url on which we receive messages from our customers:
<?xml version="1.0" encoding="utf-8"?>
<order>
<header>
<sender id="1234">Acme Inc.</sender>
<receiver id="7958">Gonzo Inc.</receiver>
<documentid>9238402934</documentid>
</header>
<items>
<item>
<index>0001</index>
<quantity>100</quantity>
<description>A regular screw</description>
</item>
<item>
<index>0002</index>
<quantity>150</quantity>
<description>A bolt</description>
</item>
</items>
</order>
The IntegrationServer should be able to parse the XML message and break it down into an internal structure of fields and values. This should also be possible if no meta information (i.e. a DTD or XML Schema) is available. In the XML example above you can see that 'item' can occur multiple times. If it appears only once in the document, a parser would not know whether to make an array out of it or not. The basic mode of operation could be to create for each XML element named 'item' a corresponding scalar field in the internal structure. The alternative would be to create an array. In order to tell the IS what to do, one would have to supply an XML Schema or some other type of definition that describes the structure of the XML message.
So the data structure should be quite flexible. The designers of the IS came up with this list of requirements:
This lead to the definition of the IData interface: com.wm.data.IData. The complete API can be viewed
here.
The only method that this interface defines returns a
com.wm.data.IDataCursor object that you can use to manipulate the data:
public IDataCursor getCursor()
Also the IDataCursor object is an interface, which defines methods to actually manipulate the data contained in the IData
structure. One can move the cursor up or down or jump to a key with a certain name:
public boolean first() public boolean first(java.lang.String key) public boolean last() public boolean last(java.lang.String key) public boolean next() public boolean next(java.lang.String key) public boolean previous() public boolean previous(java.lang.String key)
Once positioned, the key and value under the cursor can be retrieved, changed or removed.
public java.lang.String getKey() public java.lang.Object getValue() public void insertBefore(java.lang.String key, java.lang.Object value) public void insertAfter(java.lang.String key, java.lang.Object value) public boolean delete()
The IDataCursor interface can be cumbersome to use. Most of the time there are no duplicate keys (and their use should be avoided
at all cost as it only leads to confusion). Most java developers will be familiar with the java.util.Map interface, which provides easier semantics.
The IntegrationServer comes with a special class that implements java.util.Map and further combines the logic of IData,
IDataCursor, IDataUtil and IDataFactory: com.softwareag.util.IDataMap.
Everything in the IntegrationServer revolves around the IData concept.
External data that comes in is converted into an IData structure before it is handed off to any code for processing. Every publicly addressable method, in the context of the IntegrationServer from now on called service, acts on an IData instance.
The obvious drawback of passing around IData objects is that compile-time type checking has become meaningless. The solution for this problem is the Document Type. This is an independently defined data structure, comparable to an XML Schema, DTD or JSON Schema, that defines the structure of an IData object.
The default implementation of the IData interface is the class:
com.wm.data.ISMemDataImpl
The default implementation of the IDataCursor interface is the (inner) class:
com.wm.util.data.MemData$Cursor
The MemData class is the parent class of ISMemDataImpl and provides the bulk of the functionality.
The IS provides several extension points, offering the user a way to define its own (relatively) low level implementations. One of the
extensions is the possibility to define a custom implemenation for the IData/IDataCursor interfaces. This works through the com.wm.data.IDataFactory
class. This class provides concretes instances of IData, but also a mechanism to define a custom implemenation:
IDataFactory.register(java.lang.String name, java.lang.String className)
The way to create default or custom instances of IData ojbects is to call the create() method:
static IData create() static IData create(String name)
The designers of the IntegrationServer envisioned a programming language that would be able to act on an IData structure. They came up with a name that would appeal more to people without a technical background. They landed on the pipeline.
The language needed a way to address an object in the pipeline and they decided to use a path-like syntax:
/order/sender /order/items[0]/quantity
This path does not make any assumption of what it finds at the designated location. It only provides an address of the location. Anything, or
nothing, may be found there: a scalar value, an array of IData objects, or perhaps an java.io.InputStream. As duplicate keys are
allowed in the pipeline, extra syntax was needed to address the second or third occurrence of the same key:
/order/items/item(0)/@id #The first element named 'item' in the 'items' structure /order/items/item(1)/@id #The second element named 'item' in the 'items' structure
This syntax is only necessary if duplicate keys are expected. Regardless of how many time 'item' occurs, these two paths are identical:
/order/items/item/index /order/items/item(0)/index
A running IntegrationServer hosts services which are contained in packages. A service can be seen as a function. It is something that can be executed. In fact, it is the only thing that can be executed, either by a user via some protocol (http, ftp, email) or internally by the IntegrationServer's built-in scheduler.
The service is the executable unit in the IntegrationServer
The name of a service follows the same naming convention as any other addressable thing in the IntegrationServer. It consists of a path, separated by dots, and a name, which is separated from the path by a colon. Example:
folderA.folderB.folderC:svcName
There are different types of services:
Although their implementation may be different, they all appear in the same way and can be called in the same way.
It should be clear by now that a service exists independent of the protocol that invoked it. It should also be clear, that the input (and the output) of a service is an IData structure. The IntegrationServer will transform the data that was sent, including any parameters, into an IData structure.
Every service is protected by an Access Control List. Before a service is executed, the IS checks whether the user that tries to invoke the service, is allowed on the associated Execute ACL.
The most common way - but by no means the only way - to invoke a service, is by using the http protocol. This simple example invokes
the built-in service wm.server:ping using HTTP GET and the invoke directive. You can do so by pasting this url
in a web browser:
http://localhost:5555/invoke/wm.server:ping
The first element of the path of the url is the processing directive, in this case invoke. This directive determines
how the rest of the path is interpreted and how the request should be processed. These directives exists by default:
A couple of them can be changed by the setting the corresponding Extended Setting:
The second element of the path is the fully qualified name of the service. It is however common practice to replace the colon in the service name with a forward slash, but this is entirely optional. This url is equivalent to the one mentioned above:
http://localhost:5555/invoke/wm.server/ping
The IntegrationServer returns something that the browser understands:

In order to understand why the IntegrationServer decided to return HTML, we need to look at what actually went over the line.
Using the Developer Tools of the web browser, one can inspect the HTTP request in detail:
GET /invoke/wm.server/ping HTTP/1.1
Host : localhost:5555
User-Agent : Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:135.0) Gecko/20100101 Firefox/135.0
Accept : text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding: gzip, deflate, br, zstd
Accept-Language: en-GB,en;q=0.5
Connection : keep-alive
.. : //other header fields omitted
HTTP/1.1 200 OK
Content-Type: text/html; charset=UTF-8
Content-Length: 158
<BODY bgcolor=#dddddd>
<TABLE bgcolor=#dddddd border=1>
<TR>
<TD valign="top"><B>date</B></TD>
<TD>Wed Feb 12 15:31:55 CET 2025</TD>
</TR>
</TABLE>
</BODY>
Because the request specified a preference for the format of the response (Accept: text/html), the IntegrationServer
complied and returned HTML. This is by the way the default format.
The requester could also indicate that it finds JSON acceptable. Using another tool, e.g. Postman or curl, one has control over the
request and one can then explicitly set the Accept header.
Warning: This behaviour depends on the Extended Setting watt.server.http.useAcceptHeader
being set to true. If it is set to false, then the IS reacts to the header field Content-Type for determining
the format of the response.
GET /invoke/wm.server/ping HTTP/1.1
Host: localhost:5555
User-Agent: curl/8.5.0
Accept: application/json
HTTP/1.1 200 OK
Content-Type: application/json; charset=UTF-8
Content-Length: 39
{"date":"Wed Feb 12 16:04:06 CET 2025"}
The other by default supported content type is XML:
GET /invoke/wm.server/ping HTTP/1.1
Host: localhost:5555
User-Agent: curl/8.5.0
Accept: text/xml
HTTP/1.1 200 OK
Content-Type: text/xml; charset=UTF-8
Content-Length: 131
<?xml version="1.0" encoding="UTF-8"?>
<Values version="2.0">
<value name="date">Wed Feb 12 16:22:59 CET 2025</value>
</Values>
Here something interesting happens. The IntegrationServer returns a serialized version of the com.wm.util.Values object, which served
the purpose of the IData interface up to v3.5 of the IntegrationServer. The Values object now also implements the IData interface, but its serialized
version can still be found in a couple of places, for example in some configuration files that can be traced back to the first version of the IS.
Also Document Types are actually instances of com.wm.util.Values.
In the previous examples we've seen how setting the Accept header affects format of the results. Likewise, we can sending data to the IntegrationServer
in different formats. The rules for posting data via HTTP are as follows:
By the default Content Handlers exist in the IS for these Content Types:
Let's examine a couple of different ways to invoke the service pub.math:addInts, which takes two parameters: num1 and num2
The parameters num1 and num2 are encoded as query parameters in the URL:
GET /invoke/pub.math/addInts?num1=123&num2=456 HTTP/1.1 Host: localhost:5555 User-Agent: curl/8.5.0 Accept: application/json
HTTP/1.1 200 OK
Content-Type: application/json; charset=UTF-8
Content-Length: 41
{"num1":"123","num2":"456","value":"579"}
The parameters num1 and num2 are sent in the body of the request following the rules of the
application/x-www-form-urlencoded content type:
POST /invoke/pub.math/addInts HTTP/1.1 Host: localhost:5555 User-Agent: curl/8.5.0 Content-Type: application/x-www-form-urlencoded Accept: application/json num1=123&num2=456
HTTP/1.1 200 OK
Content-Type: application/json; charset=UTF-8
Content-Length: 41
{"num1":"123","num2":"456","value":"579"}
POST /invoke/pub.math/addInts HTTP/1.1
Host: localhost:5555
User-Agent: curl/8.5.0
Content-Type: application/json
Accept: application/json
{"num1":"123","num2":"456"}
HTTP/1.1 200 OK
Content-Type: application/json; charset=UTF-8
Content-Length: 41
{"num1":"123","num2":"456","value":"579"}
Depending on the advertised Content-Type of the request, the content is parsed using the appropriate Content Handler. The result, an IData structure, is then passed as
an input to the service.
Here is another extension point: one can write a custom Content Handler and register it in the IntegrationServer. This is a relatively easy thing to do. Nice candidates would be Content Handlers for these Content Types:
multipart/form-datatext/csvBefore a service is actually executed quite some things happen. The IS:
The designers of the IntegrationServer came up with a mechanism which they call the Invoke Chain. This chain consists of a list Processors that execute in order. The easiest way to make this visible, is by provoking an exception and inspecting the java stack trace.
http://localhost:5555/invoke/pub.math/divideInts?num1=23&num2=0
This causes a java.lang.ArithmeticException: / by zero, producing this java stack trace:
com.wm.util.xform.MathDT.divideInts(MathDT.java:280) #here is where the ArithmeticException occurred pub.math.divideInts(math.java:658) sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) java.lang.reflect.Method.invoke(Method.java:498) com.wm.app.b2b.server.JavaService.baseInvoke(JavaService.java:404) com.wm.app.b2b.server.invoke.InvokeManager.process(InvokeManager.java:765) com.wm.app.b2b.server.util.tspace.ReservationProcessor.process(ReservationProcessor.java:39) com.wm.app.b2b.server.invoke.StatisticsProcessor.process(StatisticsProcessor.java:54) com.wm.app.b2b.server.invoke.ServiceCompletionImpl.process(ServiceCompletionImpl.java:243) com.wm.app.b2b.server.invoke.ValidateProcessor.process(ValidateProcessor.java:49) com.wm.app.b2b.server.invoke.PipelineProcessor.process(PipelineProcessor.java:171) com.wm.app.b2b.server.ACLManager.process(ACLManager.java:331) com.wm.app.b2b.server.invoke.DispatchProcessor.process(DispatchProcessor.java:34) com.wm.app.b2b.server.AuditLogManager.process(AuditLogManager.java:379) com.wm.app.b2b.server.invoke.InvokeManager.invoke(InvokeManager.java:637) com.wm.app.b2b.server.invoke.InvokeManager.invoke(InvokeManager.java:443) com.wm.app.b2b.server.invoke.InvokeManager.invoke(InvokeManager.java:399) com.wm.app.b2b.server.HTTPInvokeHandler._process(HTTPInvokeHandler.java:258) com.wm.app.b2b.server.HTTPInvokeHandler._process(HTTPInvokeHandler.java:85) com.wm.app.b2b.server.InvokeHandler.process(InvokeHandler.java:100) com.wm.app.b2b.server.HTTPDispatch.handleRequest(HTTPDispatch.java:183) com.wm.app.b2b.server.Dispatch.run(Dispatch.java:404) com.wm.util.pool.PooledThread.run(PooledThread.java:127) java.lang.Thread.run(Thread.java:748)
The highlighthed lines are the Invoke Chain Processors. They all implement this interface:
com.wm.app.b2b.server.invoke.InvokeChainProcessor
which defines a single method named process:
void process(java.util.Iterator chainIterator, com.wm.app.b2b.server.BaseService baseService, com.wm.data.IData pipeline, com.wm.app.b2b.server.invoke.ServiceStatus status) throws com.wm.util.ServerException
The Processor can do pretty much anything it likes, but the basic expectation is that it at least calls the next processor, which is returned by calling:
(InvokeChainProcessor) chainIterator.next()
The Invoke Chain is an elegant mechanism to inject meta-functionality (auditing, access control etc.) into the invoke stack. The obvious drawback is the extra overhead between each service invocation.
Again, there is an extension point. One can define a custom InvokeChainProcessor and register it with the IntegrationServer:
com.wm.app.b2b.server.invoke.InvokeManager.registerProcessor(com.wm.app.b2b.server.invoke.InvokeChainProcessor processor)
The custom processor will be added to the list of Processors and execute as last, but before InvokeManager.process(), which needs to execute
as last, because the method will do the actual service invocation.
Alternatively one can statically define one or more invoke chain processors in the $IS_INSTANCE_HOME/config/invokemanager.cnf configuration file.
The listed processors will be registered on startup of the IS.
<?xml version="1.0" encoding="UTF-8"?>
<IDataXMLCoder version="1.0">
<record javaclass="com.wm.data.ISMemDataImpl">
<array name="processorArray" type="value" depth="1">
<value>com.iw.invoke.StatProcessor</value>
</array>
</record>
</IDataXMLCoder>
The Java Service is the native service of the IntegrationServer, simply because the IS itself is written in Java. All the management services in the WmRoot package and the built-in services in the WmPublic package are Java Services.
The implementation is a Java method with this signature:
public static final void <service name> (com.wm.data.IData pipeline) throws com.wm.app.b2b.server.ServiceException
There are no other special restrictions. The containing class does not have to implement any specific interface, nor does it need to extend any specific class. The characteristics of the method are:
static, so it can be called on the class and does not require an instance.com.wm.data.IData object passed as a parametercom.wm.app.b2b.server.ServiceException.When a method meets these requirements, it can be registered as a Java Service in the IntegrationServer.
Usually a developer uses Designer to create a Java service in a certain folder in a certain package. Let's use an example. Suppose that the service name is:
sample.math:addInts
and the package is Sample:
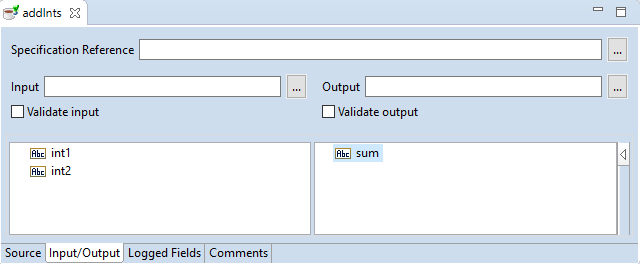
Let the inputs be int1 and int2 and let the output be sum, all of type String. The input and output together form the
signature of the service. The implementation should honour the signature, because the signature is what the IDE uses to show to the developer
what which inputs a service takes and what outputs it produces.
After creating a new Java Service and defining the signature, the following files are created:
$IS_INSTANCE_HOME/packages/SAMPLE/code/source/sample/math.java $IS_INSTANCE_HOME/packages/SAMPLE/code/classes/sample/math.class $IS_INSTANCE_HOME/packages/SAMPLE/ns/sample/math/addInts/node.ndf $IS_INSTANCE_HOME/packages/SAMPLE/ns/sample/math/addInts/java.frag
There are two files in the code directory and two files in the ns directory of the package SAMPLE.
The java source code is located in the code/source directory, the compiled code in the code/classes directory.
There is one class, namely math in the (java) package samplecontaining a static method named addInts. The
source is contained in math.java, the compiled code in math.class.
Then there are two other files under the ns folder ('ns': short for Namespace) within the package SAMPLE, namely
node.ndf and java.frag. The important file is node.ndf. This file tells the
IntegrationServer what kind of thing (node) sample.math:addInts is, namely a Java Service.
The contents of math.java:
package sample; // -----( IS Java Code Template v1.2 import com.wm.data.*; import com.wm.util.Values; import com.wm.app.b2b.server.Service; import com.wm.app.b2b.server.ServiceException; // --- <<IS-START-IMPORTS>> --- import com.softwareag.util.IDataMap; // --- <<IS-END-IMPORTS>> --- public final class math { // ---( internal utility methods )--- final static math _instance = new math(); static math _newInstance() { return new math(); } static math _cast(Object o) { return (math)o; } // ---( server methods )--- public static final void addInts (IData pipeline) throws ServiceException { // --- <<IS-START(addInts)>> --- // @sigtype java 3.5 // [i] field:0:required int1 // [i] field:0:required int2 // [o] field:0:required sum IDataMap idm = new IDataMap(pipeline); Integer int1 = idm.getAsInteger("int1"); Integer int2 = idm.getAsInteger("int2"); Integer sum = int1 + int2; idm.put("sum", String.valueOf(sum)); // --- <<IS-END>> --- } // --- <<IS-START-SHARED>> --- private static IData data = IDataFactory.create(); // --- <<IS-END-SHARED>> --- }
A couple of things to notice:
com.softwareag.util.IDataMap is used to extract the parameters from the pipeline.getAsInteger(String name) takes care of converting a string value into an Integer. It will return null if there
is no parameter named int1 or if the value cannot be parsed into an Integersum has to be put into the pipeline using the put method of the IDataMap class.Warning: the pipeline that is passed as a parameter to the method can contain anything. The java code must not rely on any value being present.
To reiterate, the pipeline (an IData object) can contain any object, including streams. The Java Service can manipulate the objects in the pipeline as it sees fit.
One can include external java libraries in a package by placing them in
$IS_INSTANCE_HOME/packages/<package>/code/jars
Libraries placed in this directory become 'visible' to any Java Service in the same package. A Java Service can import classes defined in those jars.
The class loader of the package takes care of loading and unloading all java libraries it finds in the code/jars directory.
Java Services defined in one package cannot 'see' java libraries loaded by other packages. The can however call Java Services in other packages using the invoke mechanism that the IS provides. This necessarily involves reflection (see the stacktrace above).
There is a way to let a java library contained in a package be loaded by the class loader of the IntegrationServer, namely by placing the library in:
$IS_INSTANCE_HOME/packages/<package>/code/jars/static
Such libraries are added to the class path of the IS and are usable in all packages. This seems perhaps nice, but there are at least two drawbacks:
Especially the second point causes much inconvenience for user defined packages that are regularly worked on and deployed to higher environments.
The last fundamental concept in the IntegrationServer is the Document Type. Like an XML Schema defines the structure of an XML document, an IS Document Type defines the structure of a IS Document, i.e. an IData structure. In a Document Type one can define one or more fields and for each field one can define:
null is allowed as a valueString, String List or String Table, one can specify an XML Schema built-in Data Type, and also add custom constraints, like an enumeration or a patternDocument, whether unspecified fields are allowedString, then any restriction that XML Data Type Specification supports, can be added.
java.lang.Booleanjava.lang.Bytejava.lang.Characterjava.lang.Doublejava.lang.Floatjava.lang.Integerjava.lang.Longjava.lang.Shortjava.util.Datebyte arraycom.wm.util.XOPObjectWhat is interesting is that under the hood the dimension (scalar, array, two-dimensional array) of a field is defined separately from its type.
The IDE hides this fact from the user. Setting the type of a field in the IDE to String List,
actually resuls in setting the field type to 'string' and its dimension to 'array'.
A Document Type, just like a Java Service, is defined as an artefact in a folder inside a package. Or, in IS internal terms: a Document Type is a node in the Namespace.
Just like a service, and actually any other artefact that appears in the folder structure inside a package, this document type is referred to in the Namespace as:
sample.doc:customer
The bare name of the document type is customer which is located in the folder (or interface) sample.doc.
Let's define some fields in the document type sample.doc:customer:
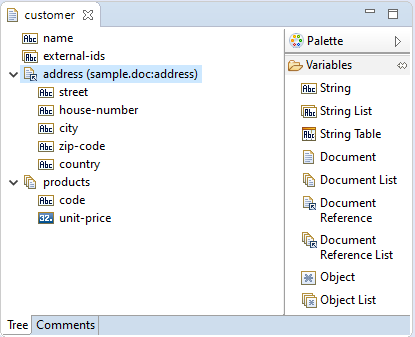
Some things to notice:
String is the dominant data type. This stems from the premise that the IS receives and sends messages in text format, being it
XML, JSON, UNEDIFACT or something else. Everything is initially a parsed text file and fields are string values.external-ids is defined as a String List. Implementation: an array of java.lang.Stringproducts is a Document List. Implementation: an array of IDataaddress is a Document Reference, i.e. the structure is defined in another Document Type: sample.doc:addressunit-price appears as a float, but one has to define it as an Object first and then further constrain it with the
Java Wrapper Type java.lang.FloatLet's have a look at the Document Type sample.doc:address, which defines the structure of the field address:
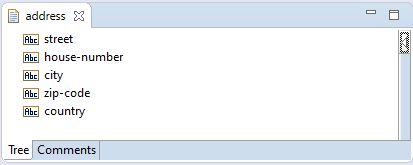
The important thing to notice, is that the Document Type sample.doc:address only defines the fields of the address. It does not
define a field named address. That name is defined in sample.doc:customer and happens to be same as the bare name of sample.doc:address.
They could have been different, say a field name ADDR referencing a Document Type sample.doc:address.
Document Types are reusable definitions. Their principle use is on the input/output of a service. When a developer wants to execute a service, the IDE will prompt the user with an appropriate input mask.
In addition to this one can use the Document Type to validate the inputs and/or outputs of a service, by ticking the boxes Validate input and/or Validate output, see the picture below:
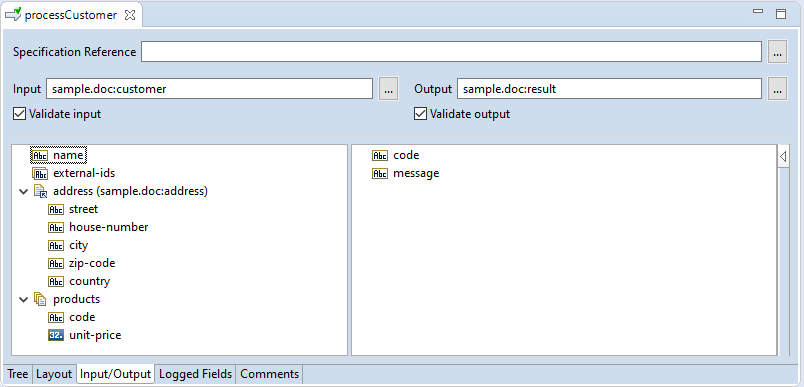
Now the service has become strongly typed. Turning on validation works as an assert statement in programming languages that support that concept.
The generic IData object should now conform to sample.doc:customer for its input and
it should return a structure that adheres to sample.doc:result. Running sample.pub:processCustomer providing only a value for the field
name results in a ServiceException:
com.wm.app.b2b.server.ServiceException: [ISC.0049.9005] Input validation for service 'sample.pub:processCustomer' failed: '/external-ids VV-005 [ISC.0082.9034] Field is absent, field must exist'
The validator is a bit lazy, as it stops processing after the first error. It would be nicer if the validator would accumulate all errors and return them all. That way it is easier to report back to the caller what the issue is. So usually
The responsible Invoke Chain Processor is for executing a validation before and after service execution is:
com.wm.app.b2b.server.invoke.ValidateProcessor
The consequence is that the calling service now has to take care of any validation errors.
The corresponding file of sample.doc:customer on the file system is:
$IS_INSTANCE_HOME/packages/SAMPLE/ns/sample/doc/customer/node.ndf
The complete definition of the document type is contained in the node.ndf file, which, for a freshly created document type, without
any fields, looks like this:
<?xml version="1.0" encoding="UTF-8"?>
<Values version="2.0">
<record name="record" javaclass="com.wm.util.Values">
<value name="node_type">record</value> #This tells the IS that it's a document type
<value name="node_subtype">unknown</value>
<value name="node_nsName">A_SAMPLE.doc:customer</value> #This is the fully qualified name of the node in the namespace
<value name="node_pkg">A_SAMPLE</value> #This defines the containing package
<value name="is_public">false</value>
<value name="field_type">record</value>
<value name="field_dim">0</value>
<value name="nillable">true</value>
<value name="form_qualified">false</value>
<value name="is_global">false</value>
<array name="rec_fields" type="record" depth="1"> #The fields are defined in this array
</array>
<value name="modifiable">true</value>
<value name="LOCK_REQUIRED">true</value>
</record>
</Values>
It's important to note that the node.ndf file is a serialized version of the document type as it exists as an object in the IntegrationServer. One manipulates
the Document Type object in the IS through the IDE (Designer), which is then saved a node.ndf file. On startup, the IS
reads all node.ndf files, deserializes them and loads the Document Type definitions in memory, just like it does with Flow code.
Let's see how this is reflected in the node.ndf file, but only for the field name. The only two things that were specified were the
field name and its type.
<!-- omitted --> <array name="rec_fields" type="record" depth="1"> <record javaclass="com.wm.util.Values"> <value name="node_type">record</value> #This field is meaningless in this context: this is not a node <value name="node_subtype">unknown</value> #This field is meaningless in this context: this is not a node <value name="node_comment"></value> #This field is meaningless in this context: this is not a node <record name="node_hints" javaclass="com.wm.util.Values"> <value name="field_usereditable">true</value> <value name="field_largerEditor">false</value> <value name="field_password">false</value> </record> <value name="is_public">false</value> <value name="field_name">name</value> #The name of the field <value name="field_type">string</value> #The type of the field <value name="field_dim">0</value> #The dimension of the field. #0: scalar, 1: array, 2: two-dimensional array <array name="field_options" type="value" depth="1"> </array> <value name="nillable">true</value> #The field may be null <value name="form_qualified">false</value> <value name="is_global">false</value> </record> <!-- omitted --> </array> <!-- omitted -->
As stated before, the Service is the central concept of a function within the IntegrationServer. But, the IntegrationServer is also capable of serving files. Most notably html pages, but it can really be anything: css, zip, jpg, csv etc.
The way this works is by not using one of the invoke directives. In that case,
the first part of the path must the name of a package. The rest of the path is the path to a file in the pub directory of said package.
So if the url in the web browser is:
http://localhost:5555/SAMPLE/index.html
then the file that is served is:
$IS_INSTANCE_HOME/packages/SAMPLE/pub/index.html
So the pub directory acts as the web root of a package. This is of course great for serving static content, but it becomes
much more interesting if the served pages could be made dynamic.
Just around, or in fact, just before the JSP specification came out, webMethods had created Dynamic Server Pages (DSP), because they needed a mechanism for the management interface of the IntegrationServer. Up to version 10.7 of IntegrationServer, the administrative interface (aptly called Administrator), was a DSP application.
DSP's work very similar to JSP's. They're basically static html-pages with extra syntax for replacing certain parts of the content with dynamic content.
Where in JSP's one would include the results of a method, in DSP's one can include the results of a Service. The only
requirement for the IS to recognize a file as a Dynamic Server Page, is that its extension is dsp. As an example, let this be
the content of $IS_INSTANCE_HOME/packages/SAMPLE/pub/ping.dsp:
<!DOCTYPE html>
<html lang="en">
<head>
</head>
<body>
<h2> The date and time is: %invoke wm.server:ping% %value date% %endinvoke%</h2>
</body>
</html>
To access this page, use this url:
http://localhost:5555/SAMPLE/ping.dsp
So what happens is that the IS retrieves the ping.dsp file, notices that it's a Dynamic Server Page and starts processing the DSP tags.
The %invoke wm.server:ping% tag tells the IS to execute the service. The %value date% tag tells the IS to include the value
of date from the pipeline in the output.
There are moreThe complete specification of DSP can be found here.
The last piece of the puzzle is how the IntegrationServer determines whether a user is allowed to read, write or - in case of a service - execute something. That 'something' can be either:
pub folder of a package, e.g.:
For the purpose of authorization, the IS uses the concept of Access Control Lists (or ACLs), Groups and Users. A User can be part can be a member of one or more groups and each ACL has list of groups that are allowed and another list of groups that are denied access to that ACL.
Every node has four associated ACL's:
These ACL's can be either explicitly set, or inherited from the parent.
The first step is to establish the identity of the caller. It's good to note that the IS support many identification mechanisms:
If the no identification information is provided, then the Default user is associated with the call. Some resources could be accessed by anyone; they have the ACL Anonymous assigned to them, which is in fact an ACL like any other. It has the group Everybody on its Allowed list, and obviously the user Default is in this group.
Interestingly enough, the ACL information is not maintained on the nodes themselves, but in four central configuration files in the config
directory of the IntegrationServer:
$IS_INSTANCE_HOME/config/aclread.cnf$IS_INSTANCE_HOME/config/aclwrite.cnf$IS_INSTANCE_HOME/config/acllist.cnf$IS_INSTANCE_HOME/config/aclmap_sm.cnfThe purpose of the first three is clear from their name. The fourth contains the Execute ACL information.
Each of the four files has the same structure. It's a serialized com.wm.util.Values object with a list of nodes and
the associated ACL:
<?xml version="1.0" encoding="UTF-8"?> <Values version="2.0"> <value name="wm.server.packages:packageCreate">Developers</value> #leaf <value name="wm.server.security">Administrators</value> #interface/folder <value name="wm.administrator.util">Internal</value> #interface/folder <!-- omitted --> </Values>
Note that an ACL can also be set on a folder. Children without an explicitly set ACL will inherit the ACL from the parent.
As the ACL information is not maintained on the nodes (or in the packages for that matter), this information, without the appropriate actions, gets lost when a package is deployed to another environment.
Nodes can be protected by non-existing ACL's. It's prefectly legal to refere an ACL in one of the acl*.cnf files that does not exist in the IS. The effect will be that no one will be allowed the corresponding access to that node.
Authorization for web resources (HTML files, DSP pages etc.) does get stored in the package itself. Each folder can/may/should
contain a .access file, which specifies which resource is protected by which ACL. There is no difference can be served. The format of the file is very simple: each line
contains a resource name (wild cards are allowed) and the associated ACL. Example:
webMethods.js Anonymous webMethods.css Anonymous * Administrators