© IntegrationWise, 2026
So you think you know what the webMethods Pipeline is and how it works, right? Because you have been using it for years and years.
No surprises there. Has been working like a charm, stable, solid, reliable. You have been coding Flow Services like forever, used
implicit mapping, sometimes unticked the box Overwrite pipeline value and even used a Conditional Mapping here and there.
And you certainly kept far away from duplicate keys, because you know how confusing that can be.
Well, you might be in for a few Really?'s, and What the heck!'s.
Chances are about 99% that you unknowingly have been producing Flow Code that contains pipeline addressing syntax that for dealing with duplicate keys. If you're curious how that might have come about, then skip straight away to the section How duplicate key syntax is introduced.
The key insight is that the Pipeline, or more precise, the com.wm.data.IData interface
(already introduced in the blog about the IntegrationServer),
is not your traditional collection of key-value pairs like for example
java.util.Map or a dictionary in Python, in which each value is uniquely identified by its key.
Rather, the Pipeline is an ordered list of key-value pairs. There is only one constraint:
java.lang.String and not be nullLet that sink in for a moment. That is the only constraint. This has the following implications:
java.lang.Object and also nullOne can wonder about why these design choices were made. One of the reasons could be that a
pipeline should be able to hold a parsed XML or HTML document. These formats allow elements like <customer>, <p>
or <div> to occur more than once. It would be nice if the parser could just add the element and its value to the pipeline
without having to wonder whether to create an array out of them or not.
Let's find out what the practical implications are. First, let's try duplicate keys. For this we don't have to pull any obscure tricks. Duplicate keys are directly supported by Document Types and hence also on the input and output tabs of a service:
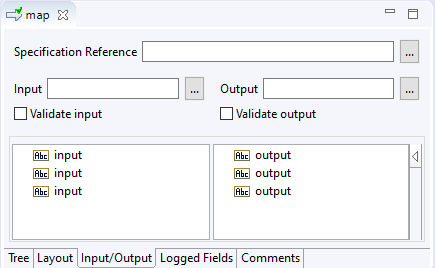
The implementation of a direct map between the three input and output fields looks like this:
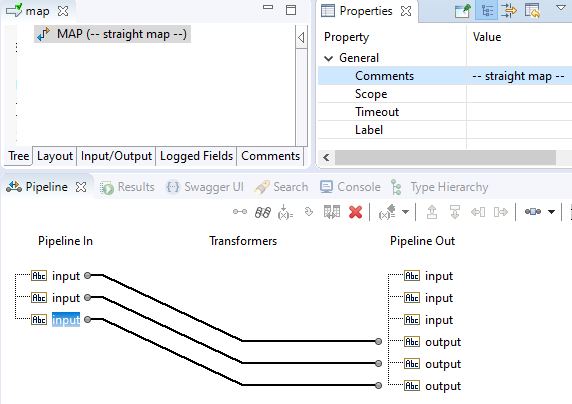
And the result if you run this service with fruity data:
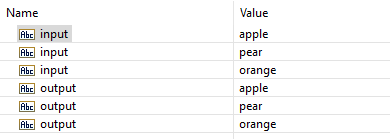
This seems to work just fine. The flow service does what it's supposed to do. The maps between the three input and
output fields behave like you would expect.
Let's now test whether we can get an entry in the pipeline with a blank key. Or better, multiple entries with an empty key. Unfortunately, this is not directly supported by webMethods. Designer complains if you try to define a field with a blank name:
![]()
Designer changes an empty field name into Untitled, if you try to remove the name.
To circumvent this problem, we need to resort to java code. This little Java Service will put three fields in the pipeline with blank keys, i.e. the name is an empty string:
public static final void put(IData pipeline) void ServiceException { IDataCursor idc = pipeline.getCursor(); idc.insertAfter("", "foo"); //empty key idc.insertAfter("", "bar"); //second empty key idc.insertAfter("", "baz"); //third empty key idc.destroy(); }
The result if you execute this service:
![]()
This fact should give rise to a little shudder. It will be very unpractical to work with blank keys, certainly in Flow Code, but it is definitely possible that the pipeline contains entries with blank keys.
Just to complete this section: as far as I was able to establish, there is no restriction on which characters can be used in a field name.
Any UNICODE character is permitted1. This piece of code:
private static void insertSpecialKeys(IData pipeline) { IDataCursor idc = pipeline.getCursor(); idc.insertAfter("\u00a5", "Yen"); idc.insertAfter(new String(new int[]{0x1F600},0,1), "smile"); idc.insertAfter("キ", "Katakana"); idc.insertAfter("\u2961", "arrow1"); idc.insertAfter("\u2962", "arrow2"); idc.insertAfter("\u2963", "arrow3"); idc.insertAfter("\u2964", "arrow4"); idc.insertAfter("\u2965", "arrow5"); idc.insertAfter("βετα", "beta"); idc.insertAfter("'\"!@A13_C$%^&*()-_`~ðé³®=+", "bananas"); idc.destroy(); }
produces this result in Designer:

#-sign. One can use it in field names, but Designer will not show any
characters past this hash-sign (and also not the hash-sign itself). It seems that the key has been modified, but that is not the case. If
you save the pipeline to file, or you call the service in another way, e.g. via a web browser, then the complete key appears again, including the hash sign.
In the blog about the IntegrationServer, the addressing syntax was already introduced, both for scalars and for arrays, but let's repeat the syntax for untyped paths here. An untyped path only refers to a location in the pipeline. The value at that location may be of any type, given the location exists in the first place.
/order/sender #The element named 'sender' in the 'order' structure /order/items[0]/quantity #The element named 'quantity' in the first element of the (first) (document) array named 'items' /order/items(1)[0]/quantity #The element named 'quantity' in the first element of the second (document) array named 'items' /table(3)[2][1] #The second element on the third row of the fourth two-dimensional array named 'table'
This untyped path can be used in Flow Services in:
Please review the documentation for Service Development for more details.
Here the waters become a bit murkier. When you create a link in a MAP step, you do not see what which (textual) paths
Designer actually uses. Designer just shows you the lines between the variables in the pipeline.
Let's have a look at what ended up in the flow.xml file after creating the pipeline.services:map service,
the one with the three input and three output fields:
<MAPCOPY FROM="/input(0);1;0" TO="/output(0);1;0"></MAPCOPY> <MAPCOPY FROM="/input(1);1;0" TO="/output(1);1;0"></MAPCOPY> <MAPCOPY FROM="/input(2);1;0" TO="/output(2);1;0"></MAPCOPY>
This seems in order. We see /input(0);1;0 being mapped to /output(0);1;0, /input(1);1;0 to /output(1);1;0 etc.
Now, what happens if we delete the first link in Designer? As we expect, the first MAPCOPY disappears from the flow.xml and the other two
remain:
<MAPCOPY FROM="/input(1);1;0" TO="/output(1);1;0"></MAPCOPY> <MAPCOPY FROM="/input(2);1;0" TO="/output(2);1;0"></MAPCOPY>
Now run the modified service again with the same fruity data:
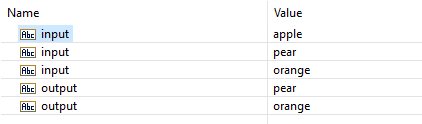
We observe that indeed the second occurrence of input (the pear) and the third occurrence of input (the orange) were selected
for the map (the FROM-clause). And we also see two fields named output with indeed the value 'pear' and 'orange'.
But wait a minute! Why do we not see three fields named output? The TO-clauses specified to map to the second and the
third occurence of the field named output. But what happened is that the values were mapped to the first and the second field
named output. Isn't that strange?
Let's run another experiment. Let's add a MAP step before this map and assign a value ('melon' for example) to the
(first) occurrence of the output field.
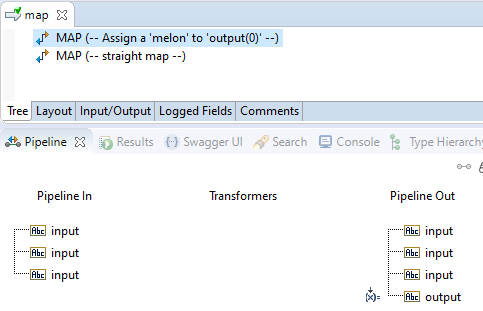
When we execute this service with the same inputs, this is the result:

We see now three fields named output. The first contains the value melon, the second pear and the third orange.
So we must conclude that a link in a MAP step that uses a positional indicator, shows different behaviour, depending on the the contents
of the Pipeline!
In short, the rule can be summed up like this:
The MAPCOPY will not create missing fields when it's supposed to map to the nth occurrence of a field.
This is a rather disturbing conclusion. This means that there is a asymmetry in the FROM selection rule and the TO
assignment rule. This in contrast to mapping to elements in an array. If you map to the nth element and the previous ones do not exist, then
the missing elements will be created with a null value.
Consider this map in which the field name is mapped to the third element of the array names:
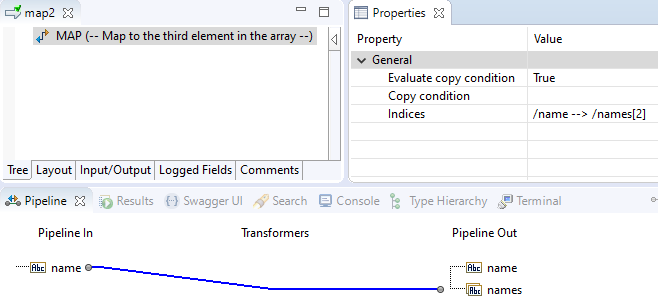
with this result:
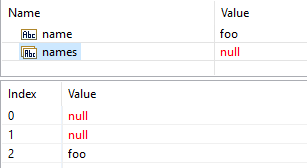
As the first and the second elements of the names array did not exist, they were created and initiated with a null value.
Overall, the conclusion should be that working with duplicate keys is a bad idea and nobody really consciously does it. Yet:
There is a 99% chance that somewhere in your Flow Code you have mapping syntax that suggests you expect to
be dealing with duplicate keys. Either in a MAPSET, MAPCOPY or MAPDELETE you'll
find a zero between parentheses:
/path/to/variable(0)
Scan your code base with a recursive grep for (0) and be suprised how many times you'll find this. Fortunately,
this is pretty harmless. Semantically /path/to/variable(0) is the same as /path/to/variable.
However, there is a 50% chance that you'll find a one between parentheses:
/path/to/variable(1)
OK, I don't have any data to back up this claim, but chances are, that you also find this in one of your Flow Services. This could possibly cause unwanted behaviour.
The mechanism by which you get syntax for dealing with duplicate keys in your Flow code, is fairly straightforward. It
usually happens when a developer decides to replace an inline-defined structure with a reference to a document type. Let's assume
your pipeline.services:parent Document Type looks like this:
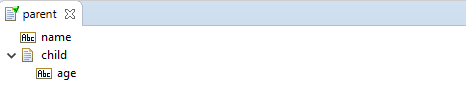
And you use this as the output of you mapping service pipeline.services:map4:
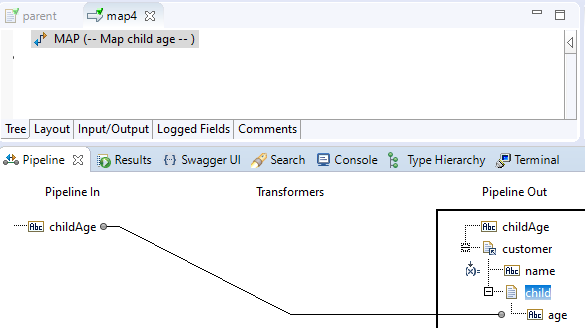
At that point, the MAPCOPY statement in the flow.xml file looks like this:
<MAPCOPY FROM="/childAge;1;0" TO="/customer;4;0;pipeline.services:parent/child;2;0/age;1;0"></MAPCOPY>
Those are nice, typed paths. No numbers between parentheses to suggest we're dealing with duplicate keys
After some time, a developer decides to give the child its own Document Type and let the parent refer
to the new structure, like this:
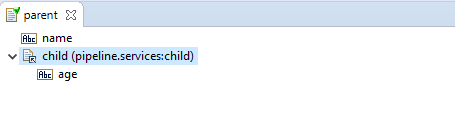
When he now switches back to the flow service, he sees that the reference to the pipeline.services:child has appeared in the Pipeline Editor:
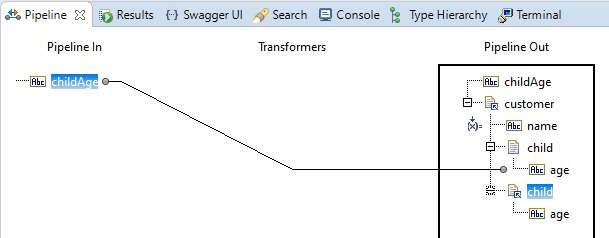
... and he decides to remap the childAge field to the age field in the referenced child document type, like this:
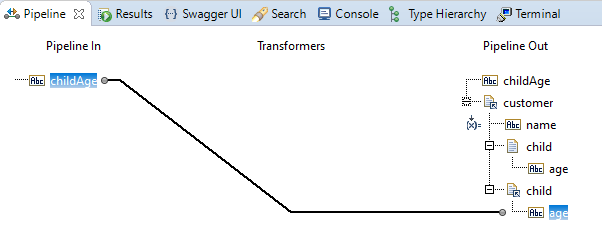
And after saving the flow service, Designer had had time to re-evaluate the 'Pipeline Out' panel and presents it like this:
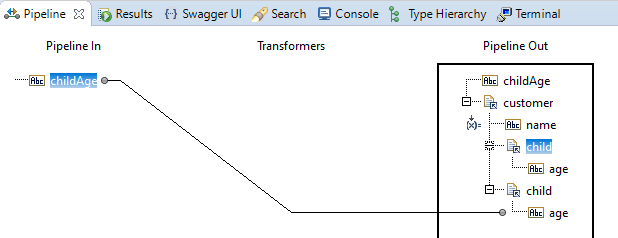
You might be surprised about the two occurrence of the child field (both referencing pipeline.services:child, but
that's a direct effect of the remap.
The MAPCOPY in the flow.xml file looks now like this: behold the (1) in the TO-clause:
<MAPCOPY FROM="/childAge;1;0" TO="/customer;4;0;pipeline.services:parent/child(1);4;0;pipeline.services:child/age;1;0"> </MAPCOPY>
That's is certainly not the way the developer meant it. In order to get rid of the second occurrence of the child field, he deletes the mapping and
redraws the line to the first child:
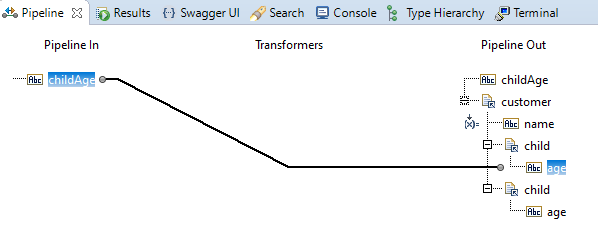
When he now saves the Flow Service, the second occurrence of the field child disappears and the mapping looks just the way he likes it:
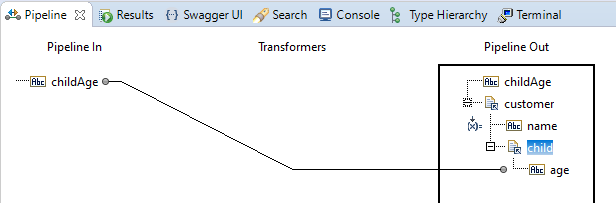
However, in the flow.xml, there remained the indication that the mapping from childAge went to the first occurrence of the field child:
<MAPCOPY FROM="/childAge;1;0" TO="/customer;4;0;pipeline.services:parent/child(0);4;0;pipeline.services:child/age;1;0"> </MAPCOPY>
As stated above, I do not have any hard data to back the percentage claims up, but I would love to gather some data. If you did a scan of your Flow Code base and if you're willing to share your findings, please drop me a line at idbaat_at_integrationwise_dot_biz. Interesting to know would be:
Your data will be treated confidentially and will not be shared with (or sold to) third parties. Only aggregations may be ever published and only on this website